Univerza v Ljubljani s partnerji gradi velik jezikovni model za slovenščino.
Gre za vrsto umetne inteligence, zasnovane za obdelavo, razumevanje in ustvarjanje besedila, ki je podobno človeškemu.
Uči se od ogromnih zbirk podatkov, ki navadno vsebujejo milijarde besed iz različnih virov, kot so spletna mesta, knjige, članki in transkripcije govorjenih besedil.
Veliki jezikovni modeli, kot je na primer ChatGPT, lahko opravljajo številne naloge, kot so odgovarjanje na vprašanja, ustvarjanje in povzemanje besedila ter prevajanje.
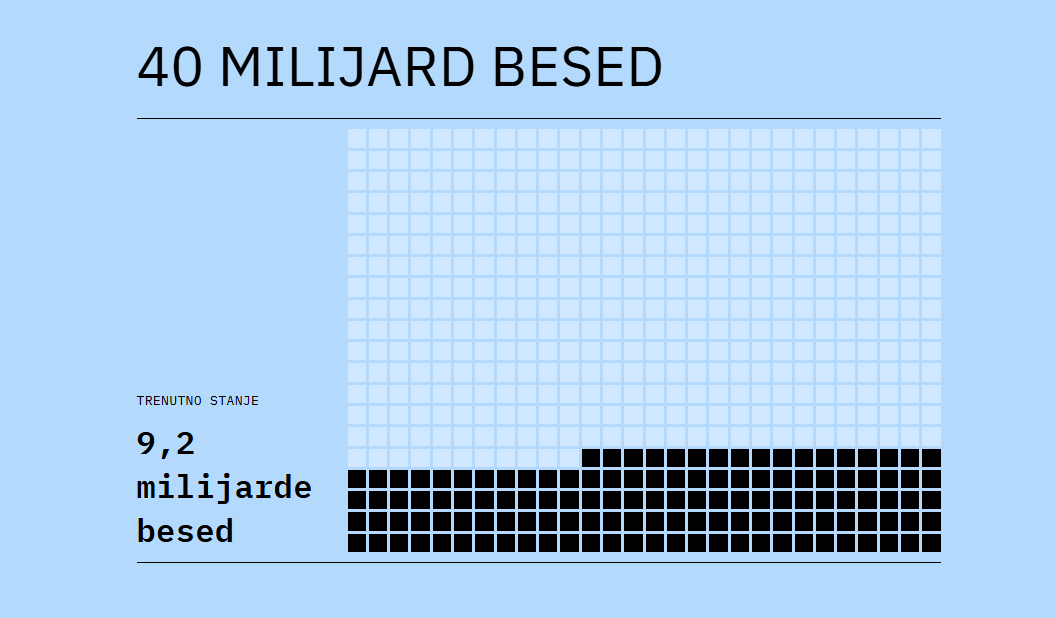
Ustvarjalci velikega jezikovnega modela za slovenščino so ocenili, da potrebujejo besedila v obsegu 40 milijard besed. Zato organizirajo nacionalno zbiralno akcijo, v kateri lahko prispevate pisna in govorjena besedila v slovenščini.
S sodelovanjem boste omogočili razvoj varne, kakovostne in odprto dostopne umetne inteligence v slovenščini.
Posredujete lahko besedila, za katera imate avtorske pravice, torej ste avtor oziroma avtorica besedila in imate avtorske pravice za svoje delo ali imate avtorske pravice za dela drugih avtorjev in avtoric.
Besedila lahko oddate na povezavi.

